
Recent flagship smartphones are integrating dual cameras, enhancing the camera user experience in various ways. To create improved image quality, the two images generated by these dual cameras need to be combined into a single image, providing higher resolution, better low-light performance, lower noise levels and other photography features not available from a single image. The process of combining these two images into a single image is known as image fusion.
In smartphones, dual camera image fusion comes into play in several ways. The first employs a dual camera with one color sensor and another monochromatic sensor (with the Bayer filter removed). The monochromatic sensor captures 2.5 times more light and thus reaches better resolution and signal-to-noise ratio (SNR). By fusing the images coming from both cameras, the output image has better resolution and SNR, especially in low light conditions.
The second approach is a zoom dual camera – A wide field of view camera coupled with a telephoto narrow field of view camera. In this case, image fusion improves the SNR and resolution from no zoom up to the point the telephoto camera field-of-view is the dominant one. In this low zoom factor range, the fusion utilizes the fact that few Tele pixels are mapped into the fusion image. This means that the output fused image is comprised from 1 pixel from the wide pixel and number of pixel from the Tele, resulting in better SNR and higher resolution.
Performing image fusion presents several algorithmic challenges:
Corephotonics’ image fusion algorithm deals with the above challenges, while requiring minimal processing load, fast run time and optimal resource utilization of the application processor. Having a mature, well tested algorithm significantly reduces the chance of image artifacts, which are unacceptable in today’s uncompromising mobile imaging world.
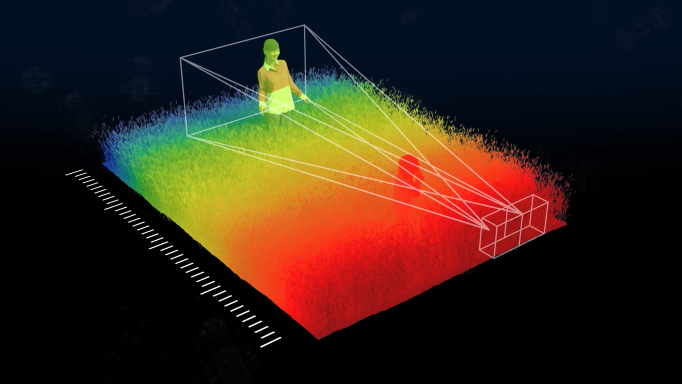
Corephotonics’ depth algorithm is based on stereoscopic vision, similar to that of the human eye. We use our dual cameras to produce a dense, detailed and accurate depth map of the scene.
In stereo vision, objects close to the camera are located in different regions of each image. As the object moves further away from the cameras, the disparity reduces until, at infinity, the object will seem to be at the same place in both images. A stereoscopic depth map is based on such camera disparities.
The Corephotonics depth map algorithm is uniquely designed to deal with various challenges, while requiring minimal load from the application processor. Such challenges include:
The algorithm is highly optimized not only for accuracy but also for real-time execution on smartphone application processors, up to 30fps, while maintaining a low memory footprint.
In turn, such depth maps can be used for various applications, including:
We are all used to zooming in and out before snapping a picture in order to get the framing right, and to zooming in when recording a video in order to highlight the most important part of the scene. When we pinch-to-zoom using our camera app, we are used to a natural, continuous zooming experience, similar to a true optical zoom experience on a DSLR.
With Corephotonics’ dual camera optical zoom, the user experience is the same, but dramatically better: zooming in with Corephotonics’ zoom dual camera gives users the same smooth, fluid experience they are used to, but instead of digitally zooming in, both cameras are used to provide optical zoom quality.
Corephotonics’ software library smoothly transitions from one camera to the other, avoiding a noticeable “switch” or “jump”, which is evident in competing solutions. The software analyzes the frames from both cameras, corrects for assembly inaccuracies and for color and luminance mismatches, accounts for imperfect optics and takes care of parallax. It also supports optical and electronic image stabilization (EIS).
For every frame in the video stream, the output frame from the library, On (x,y) , is calculated as a combination of the wide frame, Wn (x,y) , and the tele frame, Tn (x,y) , according to the following formula:
On (x,y)=αn (n,x,y,zf…) Pn {Wn (x,y)}+(1-α(n,x,y,zf…)) Qn {Tn (x,y)}
The transformations Pn {…} and Qn {…} warp the input frames according to a projective transformation, and function α(…) c controls how the frames are combined. Together, they guarantee smooth transition when zooming in.
The Corephotonics libraries optimize image quality for video recording and for preview, while keeping the camera native high frame rate (from 30fps to 120fps) and maintaining lowest power consumption.
Image quality
Camera hardware
Computer Vision